Input Variable Properties
In the Define Input Variables step, various input variable properties can be modified from the Bounds, Modes, and Distributions tabs.
Bounds
- Lower bound
- Lower limit of the variable range to be studied.
- Nominal
- Default value of the variable if deactivated; also serves as the initial value in an Optimization.
- Upper bound
- Upper limit of the variable range to be studied.
Data Type
- Numeric
- Variable stored as numerical value.
- String
- Variable stored as a character without any numeric meaning.
Format
- Continuous
- Input variable that can take any value between the lower and upper bounds, for example 1 < x < 2.
- Fixed Precision
- This controls the number of digits on the right side of decimal point. For example, if precision is set to 2 for 1.478, the outcome becomes 1.47.
- Format Descriptor
- This option controls the total number of digits and decimal point of values between lower and upper values. For example, for 0 < x < 1, %0.2f will produce values like 0.11, 0.23, 0.37, etc.
- Step
- This produces ordered values between lower and upper bounds based on user-defined step size. For example, 0 < x < 1, step size = 0.2 will produce values of 0.0, 0.2, 0.4, 0.6, 0.8, 1.0.
- List
- Input variable that can take values from a non-ordered list of values, for example x = red, green, blue or 3, 2, 7, 11.
Distribution
Input variables can be statistically characterized using various probability distributions. In statistical terms, an input variable is referred to as a random variable. While the term "random variable" may imply unpredictability in everyday language, in statistics it refers to a variable whose possible values and associated probabilities are known.
Input variables exhibit different properties depending on the parameter they represent. Some may be symmetrically distributed around the mean, while others may be skewed to the left or right. Variables can also be either bounded (limited to a specific range) or unbounded.
Variability in input variables falls into two categories: controllable and random. Controllable variability refers to variation within a known range, such as a sheet metal thickness of 6 ± 0.3 mm. In contrast, random variability (also called noise) is uncontrollable, such as fluctuations in wind speed during an open-air test.
Random variables can be continuous or discrete. A continuous random variable can assume any value within a given interval, while a discrete random variable can take only a finite set of values.
HyperStudy supports various types of distribution schemes. The most commonly used is the normal (Gaussian) distribution, where values are symmetrically distributed around an expected (mean) value. This expected value is often derived from an optimization process or trade-off study. Variation around the mean can be described using one of three measures: variance, standard deviation, or coefficient of variation.
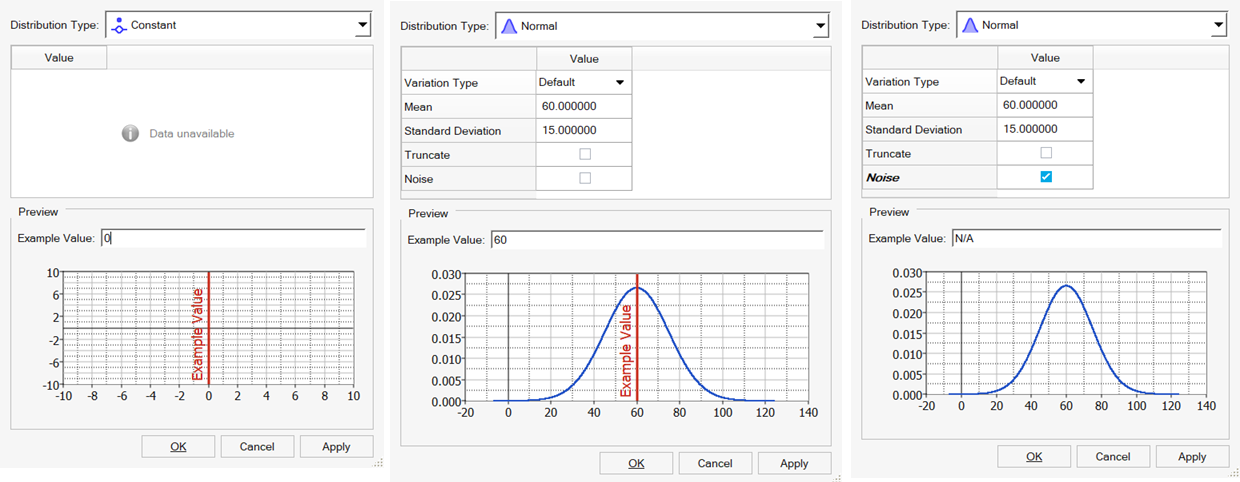
- Normal (CoV or Variance)
- Use to approximate many phenomenons in nature.
Figure 2. 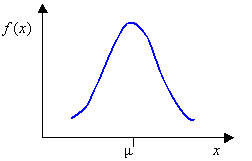
where is the mean and is the standard deviation.
- Uniform
- Use when all values between the minimum and maximum are equally likely,
such as a number from a random number generator.
Figure 3. 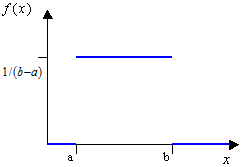
where and are end points.
- Triangular
- Use when the only known information is the minimum, the most likely, and
the maximum values.
Figure 4. 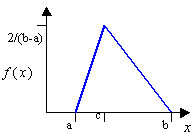
where , , and are the end points and the mode.
- Exponential
- Use to describe the amount of time between occurrences, mean time
between failures.
Figure 5. 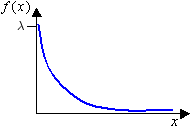
where is the scale parameter.
- Weibull
- Principal applications are situations involving wear, fatigue and
failure, failure rates, life-time expectancies.
Figure 6. 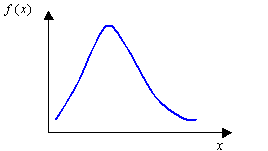
where and are shape and scale parameters which enable it to be adjusted to desired fatigue or reliability laws.
- Log Normal
- Use in risk analyses.
Figure 7. 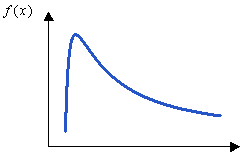
where and are location and scale.
- Uniform Discrete
- Use when you have discrete (numeric or string) variables that take values which are equally likely.
-
Figure 8.