From the Post Processing step, click the Diagnostics
tab.
In the work area, select the output response to analyze.
Click the tabs, below the output responses, to change the diagnostics used to
analyze the selected output response.
Detailed Diagnostics displays diagnostic
information for the Input matrix, Cross-Validation matrix, and Testing
Matrix.
Regression Terms displays the confidence
intervals which consist of an upper and lower bound on the coefficients of
the regression equation.
Bounds represent the confidence that the true
value of the coefficient lies within the bounds, based on the given
sample.
Change the confidence value from the % Confidence
settings. A higher confidence value will result in wider bounds; a 95%
confidence interval is typically used.
Note: Only available for
Least Squares Regression.
Regression Equation displays the complete formula
for the predictive model as a function of the input variables.
Note: Only
available for Least Squares Regression.
ANOVA estimates the error variance and determines
the relative importance of various factors.
Often used to identify which
variables are explaining the variance in the data. This is done by
examining the resulting increase in the unexplained error when variables
are removed.
Note: Only available for Least Squares Regression.
Confusion Matrix summarizes the performance of a
classifier. Correctly identified data is listed on the diagonal, and
misclassifications are presented on the off-diagonals.
Tip: Click
to toggle the confusion display from
absolute count to percentages. Also, click to control the display of the confusion
matrix between the input, cross-validation, and testing data
set.
Configure the Diagnostics tab
display settings by clicking (located in the top, right corner of the work
area). For more information about these settings, refer to Diagnostic Tab Settings.
Diagnostic Tab Settings
Settings to configure the diagnostics displayed in the Diagnostic post processing
tab.
Access settings from the menu that displays when you click (located in the top, right corner of the pane
that displays the different types of diagnostics).
% Confidence
Change the confidence value.
Note: Only available for Regression Terms
diagnostics.
Diagnostic Definitions
Definitions used to describe diagnostic concepts.
For a given set of input values, denoted as , the Fit predictions at
the same points are denoted as . The mean of the input values is expressed . For a Least Squares Regression, is the number of unknown coefficients in the
regression.
The following values are defined as follows:
Total Sum of Squares
Explained Sum of Squares
Residual Sum of Squares
Average Absolute Error
Standard Deviation
Detailed Diagnostic
Data displayed in the Detailed Diagnostic tab of the Diagnostics post process
tool.
Input Matrix
The Input Matrix column shows the diagnostic information using only the input matrix.
For methods which go through the data points, such as HyperKriging or Radial Basis
Functions, input matrix diagnostics are not useful.
Cross-Validation Matrix
The Cross-Validation Matrix column shows the diagnostic information using a k-fold
scheme, which means input data is broken into k groups. For each group, the group's
data is used as a validation set for a new approximate model using only the other
k-1 group's data. This allows for diagnostic information without the need of a
testing matrix.
Testing Matrix
The Testing Matrix column compares the approximate model, which was built using the
input matrix, against a separate set of user supplied points. Using a Testing matrix
is the best method to get accurate diagnostic information.
Criterion
R-Sqaure
Commonly called the coefficient of determination, is a measure of how
well the Fit can reproduce known data points. Graphically, this can be
visualized by scatter plotting the known values versus the predicted
values. If the model perfectly predicts the known values, R-Square will
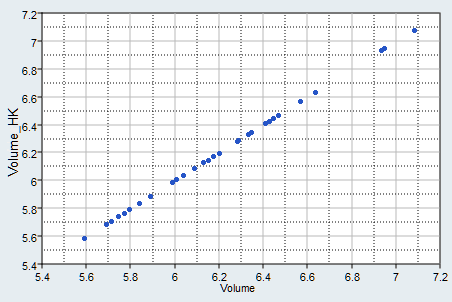
have its maximum possible value of 1.0, and the scatter points will lie
on a perfect diagonal line, as shown in the Figure 1.Figure 1. More typically, the Fit introduces modeling error, and the scatter
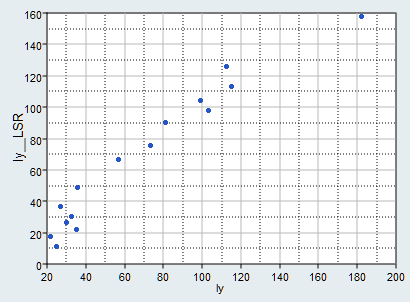
points will deviate from the straight diagonal line, as shown in the
Figure 2.Figure 2.
The value of R-Square decreases as errors increase and the scatter plot
deviates more from a straight line. The main interpretation of R-Square
is that it represents the proportion of variance within the data which
is explained by the Fit. For example, if R-Square = 0.84, then 84% of
the variance in the data is predictable by the Fit. The higher the value
of R-Square, the better the quality of the Fit. In practice, a value
above 0.92 is often very good and a value lower than 0.7 necessitates
investigation using other metrics. If R-Square is 1.0, you should be
skeptical of this result unless the data was expected to be perfectly
predicted by the Fit. There are some cases in which R-Square can be
negative. A negative R-Square value indicates that using the raw mean
would be a better predictor than the Fit itself; the Fit is very poor
quality.
In the work area, these numbers are presented with a spark line to
indicate the relative value of the number (values typically vary between
0 and 1). Values are color coded based on the following:
Red
When R2 is less than 0.65 (R2 <
0.65) it is displayed red, which indicates the value is not
good.
Green
When R2 is between 0.8 and 0.995 (0.8 <
R2 < 0.995) it is displayed green, which
indicates the value is good.
Black
Indicates that you should apply judgment when determining
whether the value is or is not good.
R-Sqaure is defined as:
R-Sqaure Adjusted
Due to its formulation, adding a variable to the model will always
increase R-Square. R-Square Adjusted is a modification of R-Square that
adjusts for the explanatory terms in the model. Unlike R-Square,
R-Square Adjusted increases only if the new term improves the model more
than would be expected by chance. The adjusted R-Square can be negative,
and will always be less than or equal to R-Square. If R-Square and
R-Square Adjusted differ dramatically, it indicates that non-significant
terms may have been included in the model.
R-Sqaure Adjusted is defined as:
In the work area, these numbers are presented with a spark line to
indicate the relative value of the number (values typically vary between
0 and 1). Values are color coded based on the following:
Red
When R2 adjusted is less than 0.65 (R2
adjusted < 0.65) it is displayed red, which indicates the
value is not good.
Green
When R2 adjusted is between 0.8 and 0.995 (0.8
< R2 adjusted < 0.995) it is displayed
green, which indicates the value is good.
Black
Indicates that you should apply judgment when determining
whether the value is or is not good.
Multiple R
The multiple correlation coefficient between actual and predicted
values, and in most cases it is the square root of R-Square. It is an
indication of the relationship between two variables.
Note: Only
available for Least Squares Regression.
Relative Average Absolute Error
The ratio of the average absolute error to the standard deviation. A low
ratio is more desirable as it indicates that the variance in the Fit's
predicted value are dominated by the actual variance in the data and not
by modeling error.
Relative Average Absolute Error is defined as:
Maximum Absolute Error
The maximum difference, in absolute value, between the observed and
predicted values. For the input and validation matrices, this value can
also be observed in the Residuals tab.
Maximum Absolute Error is defined as:
Root Mean Square Error
A measure of weighted average error. A higher quality Fit will have a
lower value.
Root Mean Square Error is defined as:
Number of Samples
The number of data points used in the diagnostic computations.
Regression Terms
Data displayed in the Regression Terms tab of the Diagnostics post process
tool.
t-value is defined as:
where βj is the corresponding regression coefficient
(the Values column) and SE is the standard error. The standard error is defined
as:
and
where cjj is the diagonal coefficient of the
information matrix used during the regression calculation.
p-values are computed using the standard error and t-value to perform a student’s
t-test. The p-value indicates the statistical probability that the quantity in the
Value column could have resulted from a random sample and that the real value of the
coefficient is actually zero (the null hypothesis). A low value, typically less than
0.05, leads to a rejection of the null-hypothesis, meaning the term is statistically
significant.
ANOVA
Data displayed in the ANOVA (Analysis of Variance) tab of the Diagnostics post
process tool.
Degrees of Freedom
Number of terms in the regression associated with the variable. All
degrees of freedom not associated with a variable are retained in the
Error assessment. More degrees of freedom associated with the error
increases the statistical certainty of the results: the p-values. Higher
order terms have more degrees of freedom; for example a second order
polynomial will have two degrees of freedom for a variable: one for both
the linear and quadratic terms.
Sum of Squares
For each variable, the quantity shown is the increase in unexplained
variance if the variable were to be removed from the regression. A
variable which has a small value is less critical in explaining the data
variance than a variable which has a larger value.
The row Error,
represents the variance not explained by the model, which is
SSerr.
The row Total, which is
SStot, will generally not equal to the sum of the
others rows.
Mean Squares
The ratio between unexplained error increase and degrees of freedom,
computed as the Sum of Squares divided by the associated degrees of
freedom.
Mean Squares Percent
Interpreted as the relative contribution of the variables to the
Fit quality, computed as the ratio of
the Mean Square to the summed total of the Mean Squares. A variable with
a higher percentage is more critical to explaining the variance in the
given data than a variable with a lower percentage.
F-value
The quotient of the mean squares from the variable to the mean squares
from the error. This is a relative measure of the variable’s explanatory
variance to overall unexplained variance.
p-value
The result of an F-test on the corresponding F-value. The p-value
indicates the statistical probability that the same pattern of relative
variable importance could have resulted from a random sample and that
the variable actually has no effect at all (the null hypothesis). A low
value, typically less than 0.05, leads to a rejection of the
null-hypothesis, meaning the variable is statistically significant.

 to toggle the confusion display from
absolute count to percentages. Also, click
to toggle the confusion display from
absolute count to percentages. Also, click