OpenMPI CUDA-aware library (shipped with nanoFluidX)
Simulations ran for equal number of time steps, therefore limiting the physical
time simulated by each case and emphasizing the realistic difference in performance
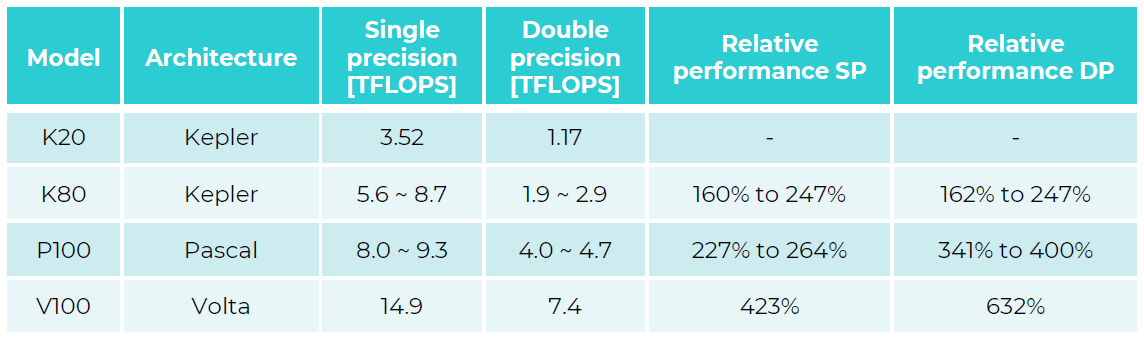
between different hardware configurations.Figure 1. Official performance numbers by NVIDIA
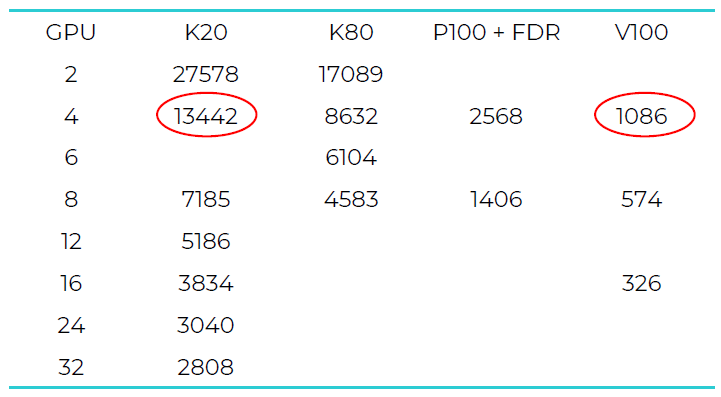
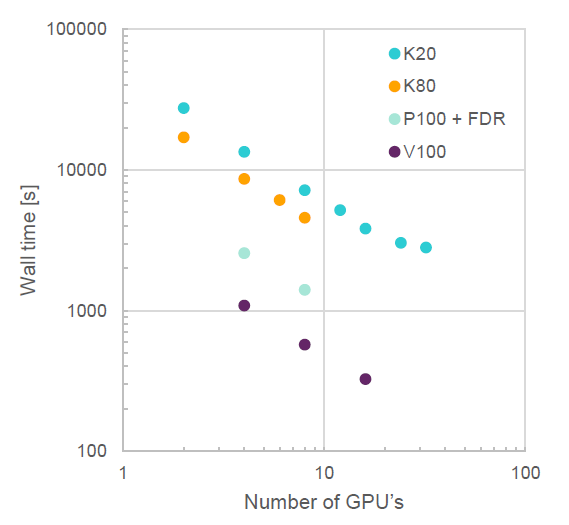
Excellent scaling is observed in all cases.Figure 2. Wall time of the simulation (s). Circled numbers indicate 12.4 times faster performance Figure 3.
Conclusions
Scaling is demonstrated for all four GPU models (K20, K80, P100 and V100), despite
having limited number of test points for P100 and V100 cards. Strong scaling
efficiency is dependent on the size of the case, implying a sufficient computational
load per GPU in order to maintain scaling efficiency. For nanoFluidX, this has been observed to be more than two
million particles per GPU.