Using Fuzzy Joins
Monarch Data Prep Studio makes an allowance for potential errors in spelling that would result in a mismatch even when the keys are highly similar (e.g., "bond" vs. "bund") during a join operation.
Such issues are addressed by using fuzzy joins.
The Edit Join dialog includes a Use Fuzzy Matching check box that, when ticked, displays a number of fuzzy matching options, including:
-
Accuracy threshold
-
Add columns for fuzzy matching results
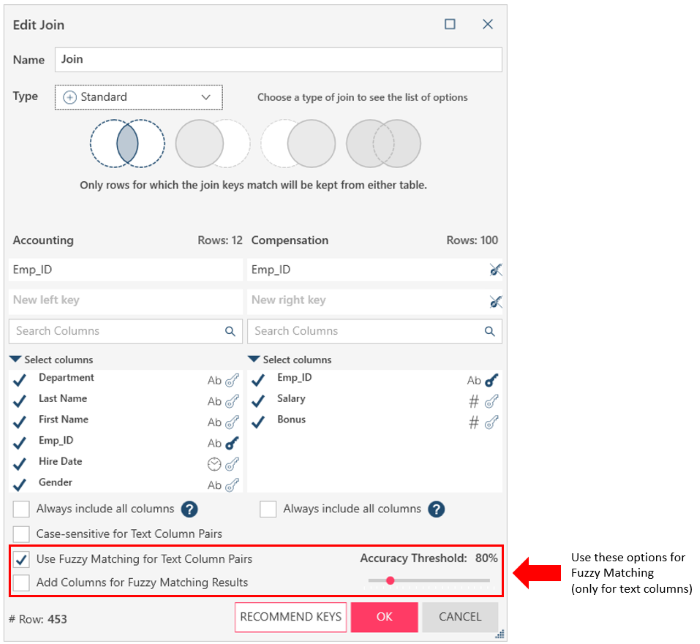
Note that fuzzy matching is only applicable to text fields.
Take the two tables below as an example:
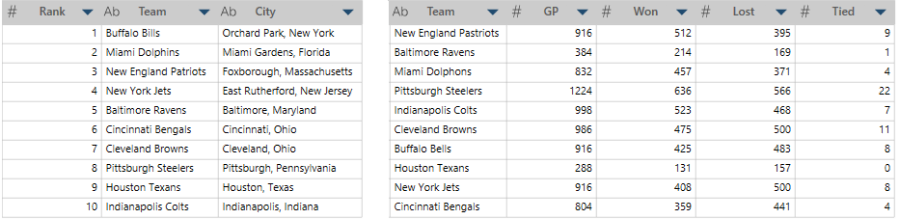
The table on the left contains the rank, names, and cities of the top 10 National Football League teams, and the table on the right specifies the game records of these teams. If we wanted to join these tables using "Team" as a key, the rows for the New England Patriots, Miami Dolphins, and Buffalo Bills would not match between tables because of misspellings in the right-hand table. To match these rows as best as possible, we will need to employ fuzzy matching.
Setting an accuracy threshold
The accuracy threshold reflects the percentage of similarity between two strings. When the accuracy threshold is set to 100% (i.e., all rows must match perfectly), only 7 out of 10 rows will match, which we already expect. Moving the slider for this setting to 90% (i.e., up to 10% of the strings may be dissimilar) changes the row count of the resulting table to 9, which means one of the three differences we identified above may be accepted in the join operation. In fact, moving the slider all the way to 0% will result in only 9 rows matched.

If we tick the checkbox for Add Columns for Fuzzy Matching Results and click OK, the following table is obtained.

A column for Key Percent Match is added to the resulting table. This column details how similar the keys between the columns are and returns this similarity as a percentage.
Interpreting fuzzy matching results
Fuzzy matching is accomplished in two steps: 1) qualification and 2) refinement. For two keys to be considered similar, Monarch Data Prep Studio computes a "Phonetic Key" using an algorithm that produces matches in a "sounds-like" manner. Once a phonetic match is achieved, refinement is performed. In this step, an "Edit Distance" (i.e., tolerance) is calculated. The edit distance is defined as the minimum number of keystrokes required to make the two keys equal (maximum of 20 strokes). These two steps are completed in sequence. Thus, if two keys are not phonetically similar (Step 1), Step 2 is no longer performed.
Because "Bills" sounds very similar to "Bulls," the rows containing these values are matched, and the percent match of these keys is considered 95%. However, because "Patriots" is phonetically dissimilar to "Pastriots," the rows containing these values are not matched even if only a very small number of strokes is necessary to match them (Step 2). The same is true for rows including "Dolphins" and "Dolphons."
Tables obtained through fuzzy matching are added to the table selector as usual and may be prepped as necessary.
© 2024 Altair Engineering Inc. All Rights Reserved.