Création d’un masque
Un masque d’extraction de données Monarch Data Prep Studio
est utilisé pour obtenir des données à partir d’un document PDF ou d’état.
Monarch Data Prep Studio
fournit sept types de masques :
Masque de détail :
Ce type de masque extrait les informations du niveau inférieur
de l’état, généralement appelé niveau de détail ou de transaction.
Les champs extraits par le masque de détail servent à créer chaque
enregistrement dans la table de base de données résultante.
Masque d’ajout :
Ce type de masque sert à extraire les champs des différents niveaux
de tri d’un état, généralement appelés niveaux de tri, de groupe ou
d’ajout. Les champs extraits par chaque masque d’ajout s’ajoutent
(par enchaînement) à chaque enregistrement créé par les champs du
masque de détail.
Masque de pied de
page de groupe : Ce type de masque extrait les champs
qui suivent une ligne de
détail (pour extraire les champs qui précèdent une ligne de détail,
utilisez un masque d’ajout). Les champs extraits par le masque de
pied de page s’ajoutent à chaque enregistrement.
Masque d'en-tête
de page : Ce type de masque sert à extraire les champs
qui figurent en tête de chaque page, On parle d’en-tête de page. Les
champs extraits par le masque d’en-tête s’ajoutent à chaque enregistrement.
Masque d’exclusion :
Les masques d’exclusion servent à préciser des lignes ou parties de
lignes qui ne doivent PAS être capturées par d’autres types de masques.
Masque de début de
région : Un sélecteur de début de région identifie la
ligne d’un état devant servir de point de départ à tous les autres
types de sélecteur (détail, ajout, etc.)
Masque de fin de
région : Un sélecteur de fin de région identifie une ligne
dans un état où tous les autres types de sélecteur (détail, ajout,
etc.) devraient se terminer.
Les instructions ci-dessous décrivent la procédure à suivre pour créer
un masque de détail. Elles s’appliquent aussi à la création d’un masque
d’ajout, de pied de page, d’en-tête ou d’exclusion.
Étape 1 : identifier et sélectionner un échantillon de masque
Importez un état PDF ou PRN dans Data Prep Studio.
La fenêtre de conception de l’état s’ouvre.
Examinez les premières pages de l’état afin d’identifier
les informations du niveau de détail. Notez si tous les champs de
détail figurent sur une seule ligne ou s’ils s’étalent sur plusieurs
lignes. Remarque : Dans
la plupart des états, tous les champs du niveau de détail figurent
sur une même ligne. Ils sont cependant parfois disposés en blocs de
deux lignes ou plus, avec, parfois aussi, des étiquettes de champ
intercalées. Dans l’illustration qui suit, tous les champs de détail
sont disposés sur une même ligne.
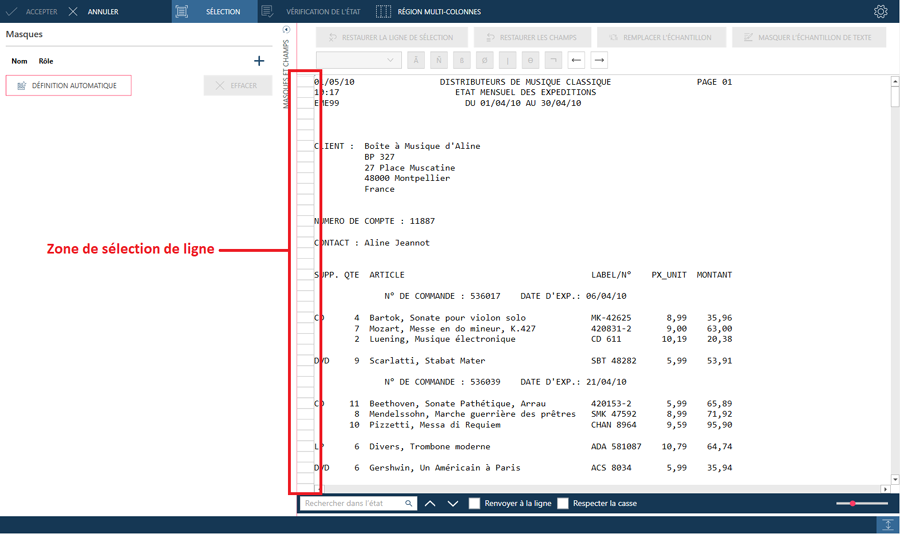
Sélectionnez une ligne ou un groupe de lignes contenant
une seule instance des champs de détail. Remarque :
Pour sélectionner une seule ligne, cliquez dans la zone de sélection
de ligne à gauche de la ligne. Pour sélectionner plusieurs lignes,
cliquez dans la zone de sélection de ligne, à gauche de la première
ligne désirée et, sans relâcher le bouton de la souris, glissez vers
le bas, jusqu’à la dernière ligne désirée.
Étape 2 : affecter un rôle au masque
Lorsque vous créez un nouveau masque pour un état, vous devez affecter
un rôle. Vous pouvez changer le rôle du masque à tout moment lors de la
création ou de la modification d’une définition de masque.
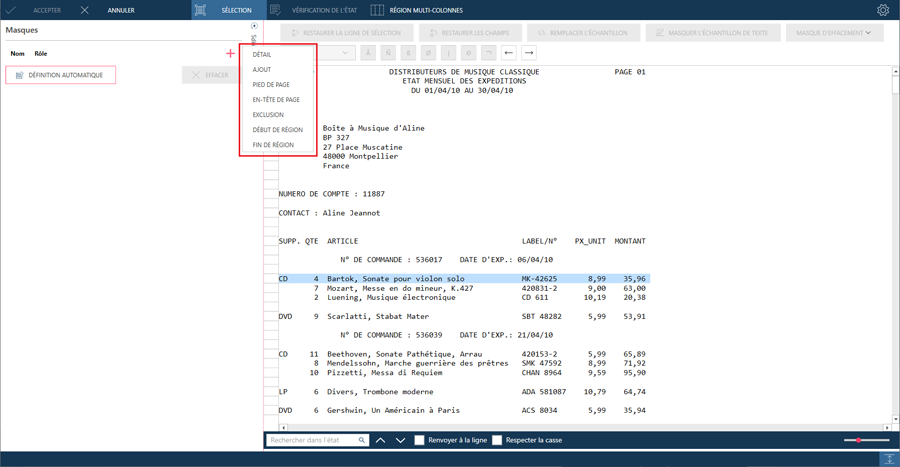
Dans le volet de propriétés du masque et du champ, sélectionnez Ajouter un nouveau masque  et sélectionnez un rôle de masque :
et sélectionnez un rôle de masque :
Étape 3 : définir un sélecteur
Un sélecteur identifiant les caractéristiques uniques du masque doit
être défini pour chaque masque. Ce sélecteur sert à capturer toutes les
instances du masque dans l’ensemble de l’état. Dans le cas d’un masque
de détail, le sélecteur identifie toutes les caractéristiques partagées,
exclusivement, par toutes les
lignes de détail. Un sélecteur de détail correct ne capture que les lignes
de détail ; il omet les lignes d’en-tête et des autres niveaux de tri.
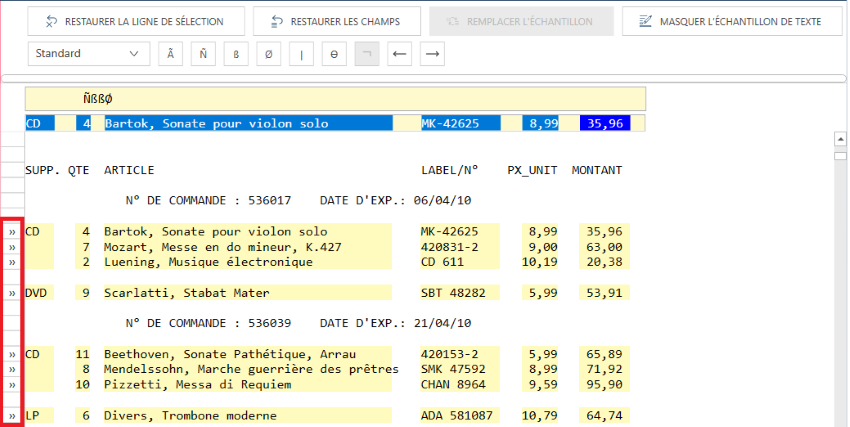
Par exemple, dans l’illustration ci-dessous, toutes les lignes de détail
présentent, en position 9, un chiffre suivi de deux caractères blancs.

Pour capturer ces lignes, il conviendrait dès lors de définir un sélecteur
recherchant, à la position 9, un caractère numérique suivi de deux caractères
blancs.
Pour créer un sélecteur, saisissez des caractères de sélection dans
la ligne de sélection comme illustré ci-dessous :
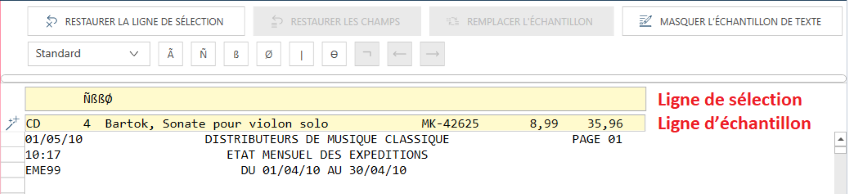
La ligne d’échantillon et la ligne de sélection. La
ligne de sélection renferme un seul sélecteur numérique défini.
Quand vous créez votre sélecteur, des portions du corps de votre état
sont marquées par des guillemets dans la zone Ligne de sélection pour
confirmer que les données qu’elles contiennent seront capturées. Vous
pouvez les utiliser pour vérifier que votre sélecteur est défini correctement.
Un ou plusieurs caractères sont admis sur la ligne de sélection. Différentes
combinaisons produisent souvent les mêmes résultats. Il est généralement
bon de spécifier plusieurs caractères de sélection pour éviter la capture
accidentelle de lignes d’autres niveaux de tri, mais faites attention
: si vous précisez trop de caractères, le sélecteur risque d’omettre certaines
lignes. Essayez différentes combinaisons jusqu’à ce que vous en trouviez
une qui vous convienne.
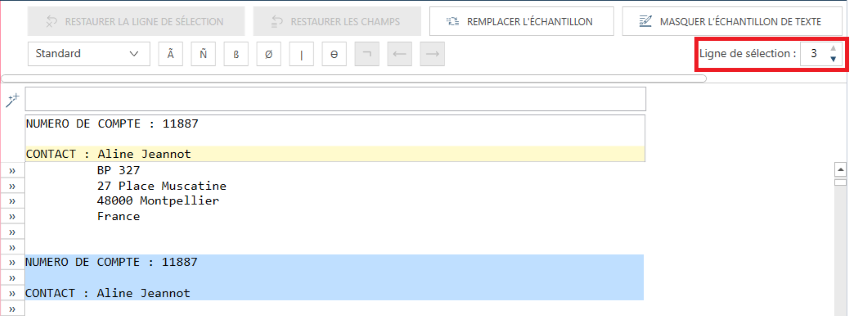
Dans certains états, les champs de détail sont présentés sur plusieurs
lignes, par ex. un bloc de texte. Il peut aussi y avoir occasionnellement
des caractéristiques uniques qui identifient la première ligne d’un bloc
de texte. S’il est impossible d’utiliser cette première ligne, sélectionnez
une autre ligne, dotée de caractéristiques uniques. Vous devez dans ce
cas indiquer la ligne d’échantillon sur laquelle opérer la sélection via
le champ Ligne de sélection.
Lorsque le sélecteur capture toutes les lignes de détail et aucune autre,
passez à la sélection des champs à extraire.
Data Prep Studio accepte plusieurs types de sélecteur, par ex. Normal, Flottant
et Regex. Vous pouvez choisir
le type de sélecteur à appliquer au masque dans le menu déroulant Type de sélecteur.
Étape 4 : sélectionner les champs et les nommer
Pour sélectionner les champs :
En utilisant la ou les lignes d’échantillon comme exemple, sélectionnez
tous les champs à extraire. Mettez suffisamment d’espace en surbrillance
pour couvrir les valeurs de champ longues, sans toutefois risquer d’envahir
l’espace d’un autre champ. Pour les champs numériques, alignés à droite,
étendez la surbrillance vers la gauche pour couvrir le plus long nombre
susceptible de figurer dans le champ.
À l’aide de la souris :
Cliquez dans la ligne d’échantillon à gauche du champ et déplacez
la souris vers la droite pour le sélectionner. puis répétez l’opération
pour tous les autres champs à extraire. Pour les champs numériques,
alignés à droite, partez de l’extrémité droite du champ et faites
glisser le curseur vers la gauche.
À l’aide du clavier :
Le clavier offre une méthode de sélection plus précise, car il permet
d’ajuster facilement la longueur des champs, un caractère à la fois.
Cliquez sur la ligne d’échantillon pour y faire apparaître le curseur
d’insertion. Utilisez les touches fléchées pour placer le curseur
sur le premier caractère du champ, appuyez ensuite sur Insérer et
sélectionnez le champ à l’aide de la flèche droite. Appuyez sur Entrée pour terminer la définition
du champ, puis répétez l’opération pour tous les autres champs à extraire.
Vous pouvez faire défiler l’état et assurer la définition correcte
des champs à l’aide du curseur de défilement vertical, mais la méthode
est fastidieuse lorsque l’état est volumineux. Pour vous faciliter
la tâche, Monarch Data Prep Studio
offre une fonction de vérification complète des champs définis.
Pour nommer les champs :
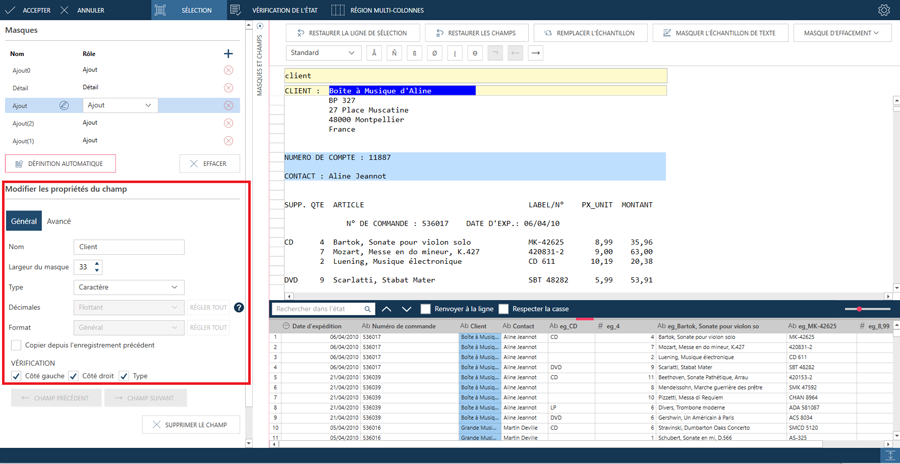
Vous pouvez nommer les champs dans la portion Propriétés
du champ du volet des propriétés
du masque et du champ. Leur désignation dans le contexte de l’état
facilite la définition de noms appropriés.
Cliquez sur un champ que vous voulez renommer dans
la ligne d’échantillon.
La portion Propriétés du champ
du volet des propriétés du masque
et du champ affiche la valeur de l’échantillon du champ sélectionné
et son nom actuel. Si vous n’avez pas encore nommé le champ, il reçoit
automatiquement un nom temporaire.
Créez un nom approprié pour le champ en cliquant dans
le champ Nom et en remplaçant
le nom existant par un nouveau nom. Cliquez sur la coche en regard
du champ pour accepter le nouveau nom.
Les noms de champ sont limités à une longueur maximale de 62 caractères.
Les caractères majuscules et minuscules sont admis, de même que les
espaces et signes de ponctuation, à l’exception du point (.), du point
d’exclamation (!), de l’accent grave (`) et des crochets ([]). Tous
les caractères sont admis en début de nom, à l’exception de l’espace
et du trait de soulignement (_). S’il est précédé d’espaces, le nom
est accepté, mais les espaces de tête sont omis.
Remarque : Si vous
choisissez d’appliquer les règles DBF, vos noms de champ doivent être
conformes aux conventions de désignation dBASE III. Ils sont limités
à 10 caractères ; les caractères alphanumériques et le trait
de soulignement (_) sont admis. Le premier caractère doit être alphabétique.
Les espaces et les signes de ponctuation ne sont pas admis.
Répétez les étapes 1 et 2 pour chaque champ devant
être renommé. Si plusieurs champs sont définis dans un masque, vous
pouvez afficher les propriétés du champ suivant et le renommer en
sélectionnant le bouton Champ suivant en
bas du volet Modifier les propriétés de champ.
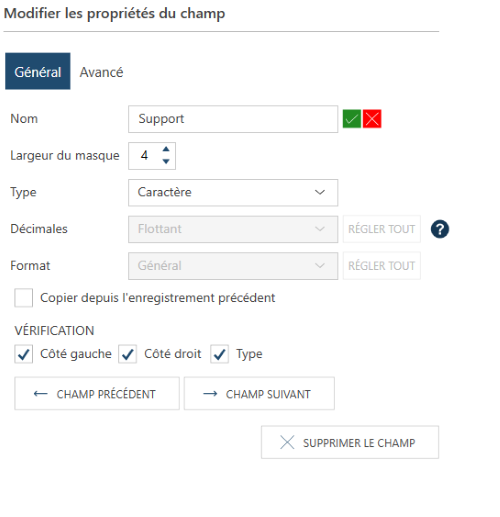
Étape 5 : modifier les propriétés de champ
Chaque champ est décrit par un ensemble de propriétés qui le rend unique
et le distingue des autres champs. Ces propriétés sont spécifiées dans
la portion Modifier les propriétés de
champ du volet Propriétés du
masque et du champ quand un champ est sélectionné dans la ligne
d’échantillon Suivez les instructions fournies dans propriétés
du champ d’entrée pour modifier les propriétés de vos champs.
Étape 6 : nommer et accepter le masque
Après la vérification du sélecteur et de la définition des champs, il
reste à nommer le masque et à l’appliquer à l’état.
Cliquez sur l’icône Modifier
à droite du nom du masque pour activer le champ de texte. Notez que,
par défaut, Monarch Data Prep Studio
affecte le rôle du masque actuel comme nom du masque.
Saisissez un nouveau nom dans le champ Nom
du masque.
Cliquez sur Accepter
dans la fenêtre de conception de l’état pour enregistrer
la définition de votre masque. Ou cliquez sur Annuler
pour supprimer vos modifications.
Étape 7 : vérifier le masque
Après avoir créé le masque, vous pouvez le vérifier pour vous assurer
de l’absence d’erreur ou de problème.
Cliquez sur l’outil de vérification
de l’état dans la barre d’outils de la conception de l’état.
La fonction Vérifier examine toutes les limites de
champ de l’état. Si un caractère se trouve tout contre une limite,
Monarch Data Prep Studio
met le champ concerné en surbrillance pour vous avertir qu’il risque
d’être trop court ou qu’il n’est peut-être pas défini au bon endroit.